Arnold Moya
Newsletter
Async escala tu sistema. Y también tus problemas.
Adoptar async es casi inevitable cuando escalas. Pero hay un costo que nadie menciona en las demos: pierdes el control sobre el orden de ejecución, y los bugs que eso genera no disparan alertas.
🔗 Fuente
Este artículo está basado en el newsletter System Design Classroom de Raul Junco. 🔗 Leer el original
⚡ El problema que nadie menciona
Los sistemas asíncronos te permiten escalar horizontalmente. Más consumidores, más throughput, más paralelismo. Hasta ahí todo bien.
El problema: cuando adoptas async, pierdes el control sobre el orden de ejecución. Y eso no es un bug. Es el diseño.
🚪 Un ejemplo que lo explica solo
Imagina un sistema IoT para una cerradura inteligente. El usuario envía dos comandos en secuencia:
- "Abrir puerta"
- "Cerrar puerta con llave"
En un sistema async con múltiples consumidores en paralelo, esos eventos pueden llegar al revés. El consumidor procesa primero "cerrar" y luego "abrir". Resultado: la puerta queda abierta.
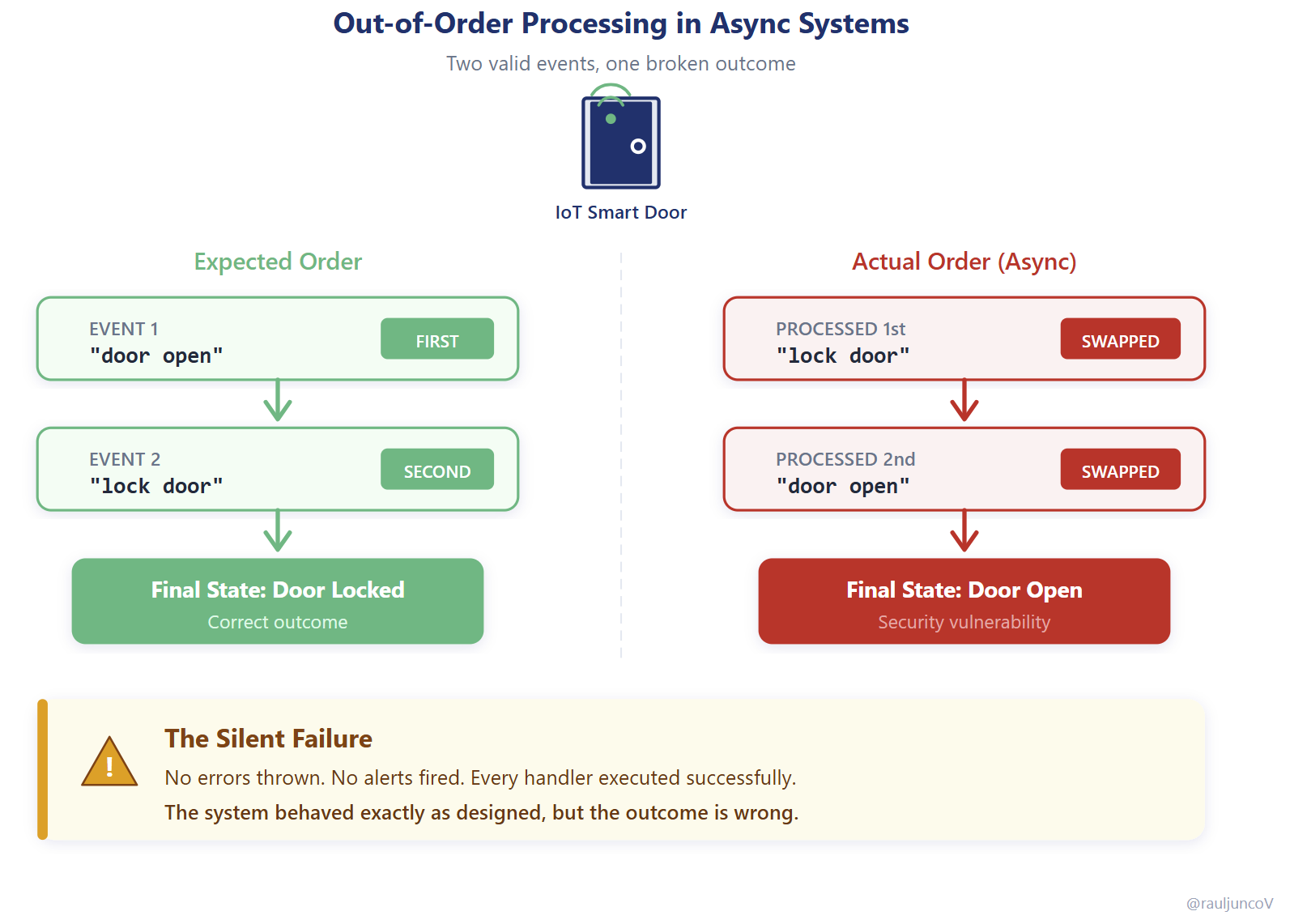
Ningún componente falló. No se disparó ninguna alerta. El sistema se comportó exactamente como fue diseñado.
Ese es el problema. Todo funciona. Y aun así, el estado final es incorrecto.
"Cada componente es localmente correcto, pero nadie es dueño de la secuencia en el tiempo."
🔀 Por qué async rompe el orden
Hay cuatro fuentes principales de reordenamiento:
- Ejecución paralela de consumidores — múltiples workers procesan mensajes al mismo tiempo
- Reintentos — un mensaje fallido se reencola y llega tarde
- Latencia de red — los mensajes no viajan a la misma velocidad
- Procesamiento en lotes — los batches mezclan mensajes de distintos momentos
El orden que ves en el productor no es el orden que ves en el consumidor.
🧩 La solución: agrupar, no serializar
La solución no es volver al mundo síncrono. Eso destruiría la escalabilidad.
La solución es agrupar mensajes relacionados para que procesen en secuencia dentro de un mismo grupo, mientras los grupos entre sí siguen corriendo en paralelo.
No estás eliminando la concurrencia. La estás moldeando.
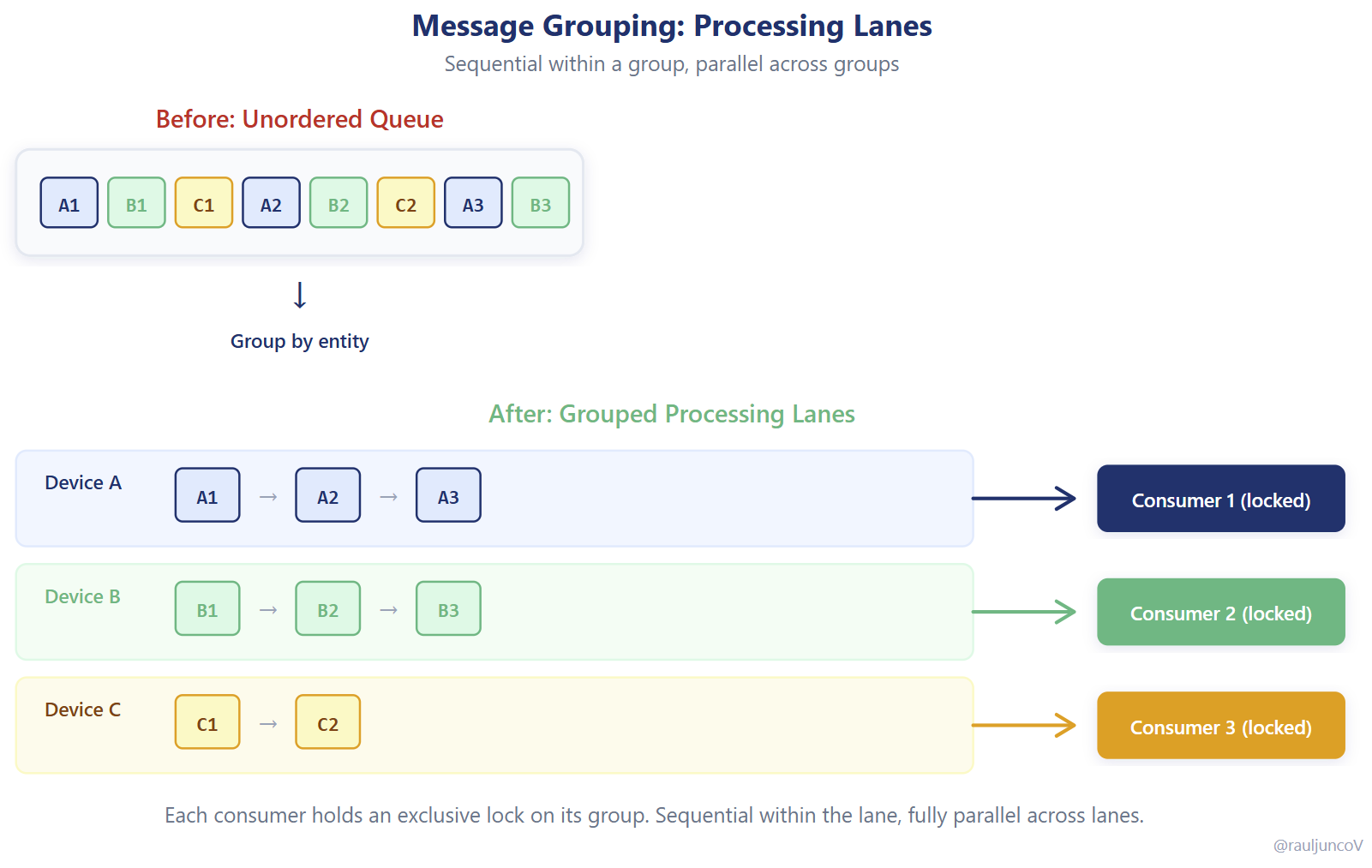
Ejemplo: todos los eventos del mismo dispositivo van al mismo grupo. Dos dispositivos distintos siguen procesando en paralelo. El orden se mantiene donde importa.
🛠️ Cómo se implementa en cada plataforma
| Plataforma | Mecanismo |
|---|---|
| Kafka | Partition key |
| SQS FIFO | Message group ID |
| Azure Service Bus | Session ID |
Cada una enforces el orden dentro de un grupo. El paralelismo sigue existiendo entre grupos.
🔥 El tramposo: hot partitions
Elegir la clave de agrupamiento mal tiene consecuencias reales.
Si usas el ID de un tenant como clave y ese tenant tiene millones de dispositivos, todo su tráfico colapsa en un solo grupo. Un mensaje lento detiene a todos los demás.
Agregar más consumidores no resuelve esto. El cuello de botella no está en la cantidad de workers. Está en el diseño de la clave.
Y lo peor: esto casi nunca se ve en desarrollo. Aparece bajo tráfico real, con distribución desigual.
💡 Qué llevarse de esto
Si estás construyendo sobre async, el orden no viene gratis. Hay que diseñarlo.
Tres preguntas que vale la pena hacerse antes de hacer deploy:
- ¿Hay entidades en mi sistema cuyo estado depende del orden de los eventos?
- ¿Mi clave de agrupamiento refleja esas entidades o es arbitraria?
- ¿Qué pasa si un tenant o usuario concentra 10 veces más tráfico que el promedio?
"Si no diseñas para el orden, async lo va a decidir por ti."